



Tape lives!
Fujifilm has a new (-ish) product called Fujifilm Object Archive that they showed off to use at Storage Field Day 22 last year. It’s basically AWS Glacier but for inside your datacentre.
Object Archive has an S3 compatible API for accessing data, so it’ll integrate with anything else that speaks S3, which is pretty much everything that needs to deal with large amounts of data, like backup systems or data and analytics software.
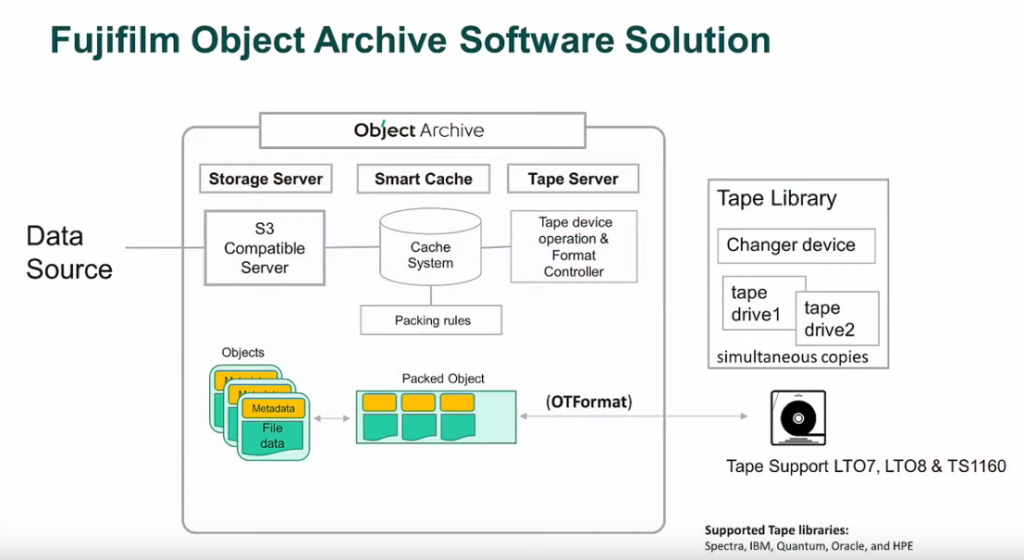
The frontend of the system is a server, backed by flash storage as a Smart Cache that is where data lands for processing, either for ingest from the network, or egress back off tape. For everything outside the system, it just looks like a system that presents S3 buckets to applications.
The back end of the system is a tape library, and Fujifilm uses a new tape format it calls OTFormat. The spec is open, so in theory anyone could implement it, and Fujifilm provide a reference reader on their website. I’m unclear on why a new tape format is needed compared to an existing format like LTFS but it seems to be a more object-centric format rather than a file-centric format. That helps for efficiency of data packing and data transport when you’re using an object format for the system as a whole.
I like tape. For storing lots of data that you need to access in big chunks, or keep on a shelf for a while, it’s hard to beat tape. It excels at long-term storage, particularly for important data you probably won’t need to restore, but need to keep just in case. It’s not as long lived as something like archival film by the likes of Piql but it’s great for a few years. Offline storage is great for ransomware protection as well, and you don’t need to keep feeding electrons to a tape to keep your data alive.
Putting something faster like—flash or disk—in front of a tape archive isn’t a new idea; we’ve been doing it with Virtual Tape Libraries for decades, and Fujifilm competitors also sell this kind of hybrid system (Spectra Logic’s BlackPearl comes to mind). But this isn’t a criticism of Fujifilm, it’s simply noting that they’re using known-good system design patterns, which is a good thing when you’re trusting important data to a system. You probably don’t want to be using some kind of early beta, buggy-as-all-getout tech for something you expect to be able to restore in six months or three years.
It’s interesting to me that Fujifilm has decided to enter this market, and how they’re talking about it.
Data Egress Charges
Fujifilm specifically mentioned data egress charges as something you don’t have with this kind of system. The frankly outrageous AWS tollbooth that is data egress charges is a massive, massive deal when you’re talking about the size of datasets that something like Object Archive is designed to serve. Object Archive starts its licensing at 1 Petabyte. If you have a couple of hundred terabytes, this is not for you.
But consider how much it would cost to pull back a few hundred terabytes out of AWS Glacier. If it’s something you need to do regularly, you’re talking thousands of dollars a month: Around $2048 USD a month just for 100TB data transfer between US East and any other region (the assumptions move the price around a lot, so check things for yourself carefully) and may Great A’tuin have mercy on you if you push anything through an API gateway or need it to go over the Internet.
This isn’t a solution for highly variable workloads: this is substantial plant that you expect to use a lot, and it’s the utilisation rate that makes it worthwhile owning rather than renting at spot prices from the public cloud. Of course, it’s not as simple a calculation as that, and we’re talking big dollars here so you need to put on your grownup pants and do your due diligence, not make a hasty decision based on one article you read on the Internet.
Or not. I’m not your Mum.
Random Factoids
Fun fact! Fujifilm have invented a new kind of magnetic particle called Strontium Ferrite which is apparently better than the existing Barium Ferrite particle. (Cue rendition of They Might Be Giants Particle Man…)
It will mean tape can store 580 TB on a single tape, about 48 times more than the existing LTO-8 tape. That’s a lot of data.
Long live tape!
Pingback: Storage Field Day 22 – Wrap-up and Link-o-rama | PenguinPunk.net
Pingback: Tape Lives! At Fujifilm - Tech Field Day