



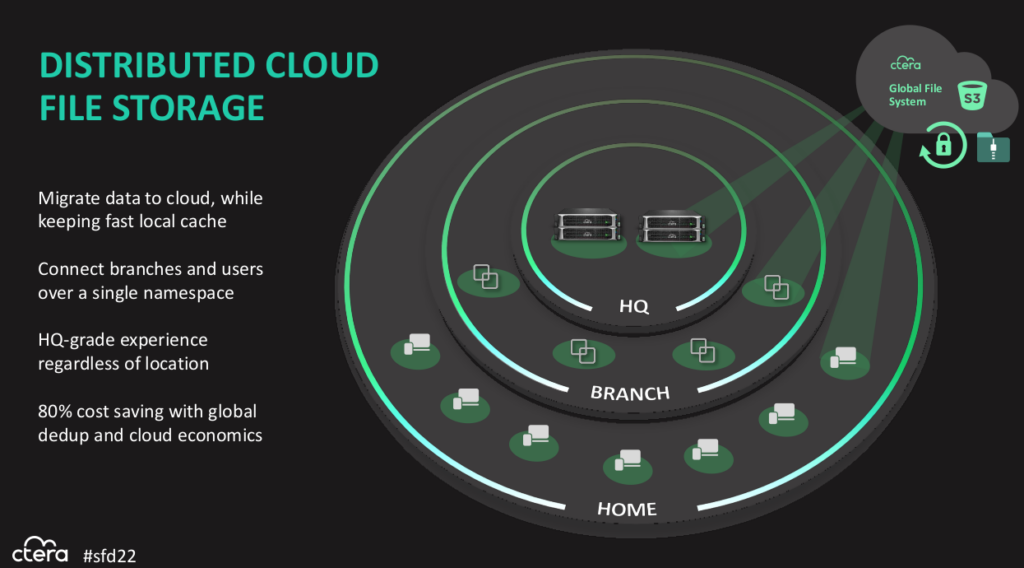
CTERA is storage software for a global filesystem accessible from anywhere in your organisation. It’s designed to be multi-cloud—meaning it can use one or more clouds, including private on-site infrastructure—but also private: only you and those you authorise can access your data.
It’s built as a client-server design, S3 services making up the server side, and client that provide access into the global filesystem. Clients include edge filers, which are caching appliances (usually hyper-converged systems with a mix of compute and storage), or desktop and mobile agents.
Interestingly, CTERA has also added a Kubernetes Container Storage Interface (CSI) agent that provides access into a CTERA namespace without, it seems, having to go through an edge filer. I’m not clear on exactly how this works, so it’s something I’ll need to follow up with CTERA about.
CTERA is software, so it creates an abstraction over the top of cloud-based S3 resources (which could be on any S3-compatible service, including a local S3 service instead of a cloud) and some flash for metadata. That means it runs on just about anything you might want to run it on, and can adapt to a variety of use-cases. CTERA is particularly keen on being useful at what it calls the far edge which is the vastly distributed set of IoT devices with relatively small amounts of compute and storage.
The other advantage of software is that it can look basically the same everywhere. If you’re accessing a file on a Raspberry Pi or a Windows Server instance in a public cloud, the file looks the same. The data looks the same. This kind of consistency-at-scale provides a lot of benefits in operational efficiency that are very worthwhile.
There’s also a challenge: The ability to share data to everywhere all over the world is great when it’s what you want to do, but what do you do when you don’t want that data shared? Maybe just not right now, or maybe not at all, ever.
Lock Down Your Sites
For the “don’t share this right now, I’m using it” use-case, CTERA uses a combination of strict consistency and locking within a customer-defined ‘site’ and eventual consistency across/between sites. It’s a combination approach that I quite like, because using a strict global locking approach introduces a lot of complexity and restrictions that most people don’t need most of the time.
Strict locking is mostly required when the software people are using doesn’t understand cross-site collaboration and so the file locking is needed to stop the software getting confused when multiple people try to work on the same data simultaneously. Compare using Track Changes in Word with online document editing in Google Docs.
Software like AutoCAD or the Adobe suite is much better at this than it used to be, so the need for strict global locking is much reduced, and there are other approaches to address the challenge of collaboration over distance now, so a lot of the reasons for needing global locking have gone away. CTERA seems to have decided that it’s just not worth the hassle and local locking provides what most customers need most of the time, so it’s a better tradeoff for them. Which is fair enough.
It also seems nicely configurable. If I can define a ‘site’ and do locking within it, I can use CTERA to suit my workflow instead of having my technology dictate to me how I have to do work. I want to be able to reflect my own organisational structure, not that of the development team that built the software. Outside of reflecting the laws of physics, it’s pretty frustrating when technology places artificial limits on what I can do with it, especially when those limits exist because it makes the developers’ lives easier, not the customers’.
Security and Locality Zones
I like that you can define locality and security policies for data to, for example, ensure that health data in Germany never leaves the country, but other data is allowed to move into the cloud for global collaboration with staff in other countries. Having better, and more granular, controls over your data before you start moving it around the place is something we should have had before now.
It’s just too easy to throw a spreadsheet full of private data into a shared folder that auto-replicates all over the place, and expecting that people will accurately perform the tedious task of carefully safeguarding other people’s data is folly. Sure, they probably should, but they’re not going to, and our systems should be designed to account for this.
In fact, I’ll go further. I’m not sure that CTERA locks things down enough by default. Really, “please leak my sensitive data to everyone” shouldn’t be our default setting and when data could only leave our computer if we copied it onto removable media and schlepped it over to another computer, it was a lot easier to keep data protected. Now, because everything is connected to the Internet (even when it really shouldn’t be) it’s extremely easy for fallible humans to make a mistake that lets data go to places it shouldn’t.
GDPR and similar privacy laws are getting passed all over the place partly as a response to this sloppy data handling, so it’s good to see the tools and technologies are finally starting to implement good, easy-to-use controls that can adapt to the way people actually work in the real world.
I can see CTERA combining really nicely with fellow SFD22 presenter Komprise to provide me with insights into where my data is and who is using it. Using the two products together, you should be able to move your data to where it’s needed most, put it on the most appropriate infrastructure, and keep it secure while saving money. What’s not to like?
Pingback: Storage Field Day 22 – Wrap-up and Link-o-rama | PenguinPunk.net
Pingback: CTERA Global File Sharing With Modern Security - Tech Field Day