



I’ve done my usual process of predicting the TripleJ Hottest 100 again for 2016. My predictions post will be next, but this time I actually took the time to look back at last year and see if I could refine my process to do a better job of last time.
This is a normal procedure when building prediction models. You take a bunch of known historical data, and use your model to make predictions. If you have enough data, you use only part of the historical data to make predictions of the second section of your historical data and see how your model goes. The computer doesn’t know that it’s dealing with data from the past. You constrain what it knows to some arbitrary part of history, and whatever comes next is “the future” as far as your model is concerned.
The theory is that if your model does well at predicting a future where you know how things turned out, then it should do well predicting the actual future you don’t know yet.
Last year, my system didn’t do very well, so I found time (for once) to go back and try to figure out why that was. I found a bunch of things that I should have done differently (if I hadn’t rushed things at the last minute, which always seems to happen because of life and real work).
Name Matching and #notmydebt
What I learned is particularly appropriate because of the ongoing #notmydebt issue with Centrelink here in Australia at the moment, and how it relates to use of data matching.
According to an anonymous leaker, Centrelink uses the following process to match the names of businesses between its own datasets and datasets it gets from the Australian Tax Office (ATO). I’ve asked the Department of Human Services to confirm or deny this is the process used—several times—but they haven’t responded other than to point to vague media statements that avoid the question.

Alleged name matching procedure used by Centrelink.
This matching method is naive and broken, not least because the trading name for a business can be completely different to the registered ‘official’ name of the company.
Matching on data with errors is quite complex, and the simple algorithm Centrelink are apparently using doesn’t deal with any of it. To see why, I’m going to use my Hottest 100 predictions for 2015 as an example of what can go wrong and how you need to be able to deal with issues.
Two Datasets
At the core of my prediction method is a matching process between two datasets, very similar to the #notmydebt matching process. I’m trying to match the names of songs in sample vote data I’ve collected with an official list of songs in the countdown. Each song in the vote data I find is a sample vote for that song in the countdown. If I collect enough of them, then I can make statistical inferences about how many votes there actually are in the real countdown. It’s the same process I’ve used for several years now, with decent results most of the time.
The songs in the countdown are scraped from the TripleJ voting website using the highly complex method of visiting each page and saving the HTML with cut&paste, then extracting the song details with a script that parses the HTML. This gives me a master list of known songs in a consistent format with few, if any, errors. It’s a nice, clean dataset for the most part.
The dataset I’m matching against this clean dataset are really messy. The data is from images scraped off Instagram, which are then OCR’d to turn it into lines of text. OCR is imperfect, and it turns out the structure of the images in 2015 made the job of matching difficult in specific ways that were actually really important.
I am emphatically not using the super-simple method of a naive word count match like Centrelink. I’m trying to match the entire string to see if it is “similar enough” to the official song in my clean dataset, using something called a Levenshtein distance. There are libraries for doing this calculation, so I don’t know why Centrelink aren’t just using one of them. I suspect the designers of their matching process didn’t know about them.
OCR errors
Here’s an example vote data image that needs to get OCR’d:

Example Hottest 100 Vote Data Image
The data in the image is actually two columns. In the left column is the artist name, right aligned, and in the right column is the name of the song, left aligned. The cells in the table also wrap the text after some number of characters.
This is actually pretty tricky to OCR well, with my limited knowledge of how to drive the program I use to do it: Tesseract. The way the line wraps work, and the lack of vertical alignment between wrapped cells between the two columns confuses the OCR, and you get this kind of output:
Everyday {FL Rod
A$AP Rocky StewanIMigueVMark
Ronson}
Joey EadaSS Paper TrailS
FKA twigs In Time
DOWNTOWN {FL Eric
NallylMelle MellKool
Moe
DeelGrandmaster
Caz}
Be Together {Fir Wild
Belle}
Macklemore & Ryan
Lewis
Major Lazer
Kendrick Lamar The Blacker The Berry
Drake Hoiline Bling
ASAP Rocky LSD
Baby Blue {FL Chance
Actlon Bronson The Rapper}
Actln Crazy {Prodr By
Action Bronson 40}
The character recognition is actually pretty good here, and most of the words are easily recognisable. Note that lots of these would utter break the Centrelink process, because it uses exact word matches instead of a string distance; like I said, it’s naive and broken. Stupid and wrong, I think I said on Twitter.
Matching Long Lines
The bigger issue for us is the lack of vertical alignment between the name of the artist and the song. Macklemore & Ryan Lewis had a song called DOWNTOWN in the list, but the song name appears much earlier in the text than the artist name. It turns out that breaks my line-by-line process of matching songs quite badly, because I need both the artist name and the song name to get a match.
That was really important in 2015, because certain songs with long names (like anything with a long list of Featuring or Producer credits) would line wrap, and that would OCR in this unaligned way. Some of those songs were high up in the countdown, like DOWNTOWN, so my process under-counted the sample votes quite badly.
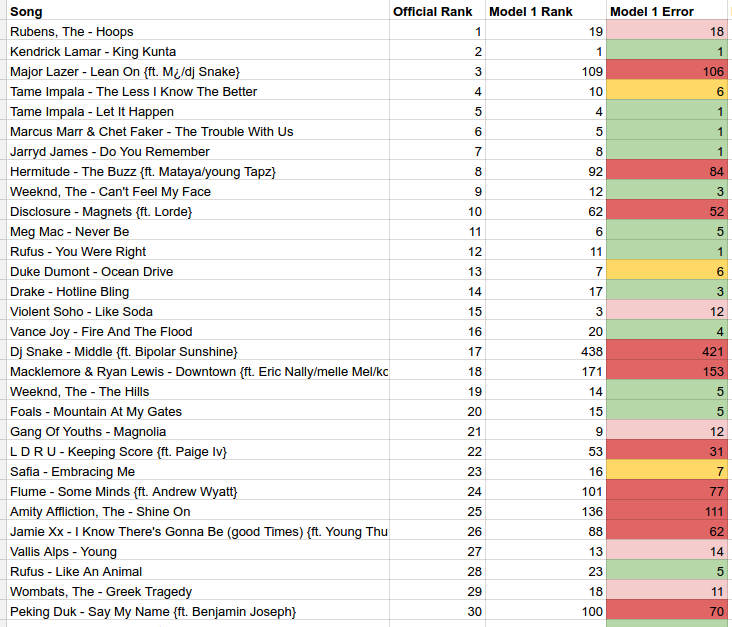
Look at all that wrongness! Humbling, innit?
Why not just match on song name? Good idea! I tried that this year in trying to get better matches, but it turns out lots of songs have the same name, so you end up with hash collisions and you’ll count all the votes against the first song with that name in the song list. *sigh*.
The good news is that I found a compromise that helps a lot. It’s not perfect, because long song titles (and artist names) still confuse the OCR (thanks Macklemore, Lewis, Peking Duk, et al) but it is a lot better.
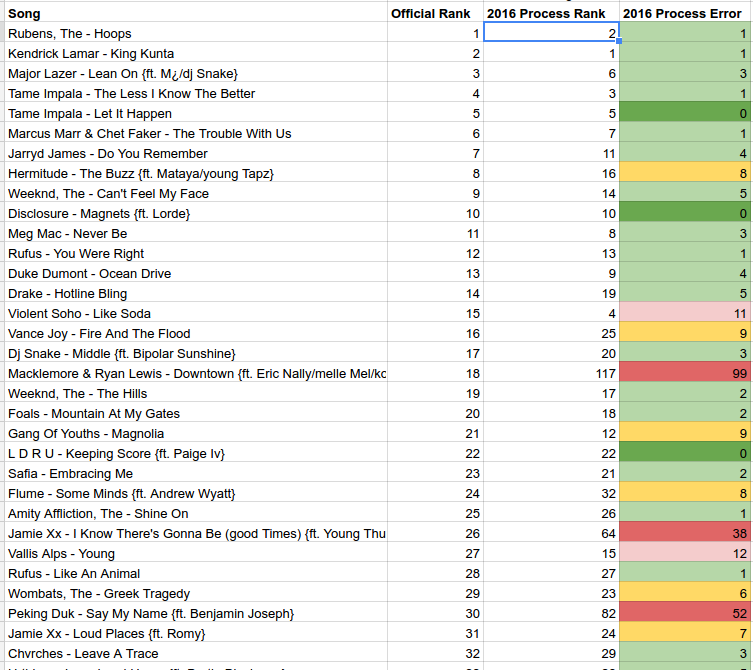
The improved 2016 model.
You can take a look at the full updated spreadsheet here.
There’s more detail on the new model in my 2016 predictions post.
Testing and Checking
All of this is to show you two things. Firstly, real data is messy. Really messy, in all kinds of weird and wonderful ways. When working with real data you will be constantly surprised by intriguing new ways that the data can be different to what you expect even before you get to the errors that creep into the data from all over the place.
The second law of thermodynamics isn’t just some abstract idea. It creeps in everywhere. Constant vigilance is the only way to deal with it, and that means testing and checking your assumptions all the time. And even then, you might still miss something.
The more ways things can go wrong, the more complex your system has to be do deal with all those error cases. For 2015, I probably needed something like a full ballot counting mechanism that would scan each separate vote as an entity and try to find enough evidence for a certain threshold number of songs before counting the vote. But then, I’d also be risking throwing away data and under-counting valid votes, which I do anyway with the simpler line-by-line method, but I throw less data away.
No choice is without consequences.
If you don’t have a pretty high degree of paranoia about how wrong your predictions are, then you’re probably going to be embarrassed when reality smacks you up the side of the head, like I did last year.